

Neural Density Estimation via Diffusion
Say you have a bunch of data, . Where , and . In the GenAI™ paradigm, we typically want to sample more data from . Typically, 's could look like images, or audio, etc. At the time of writing diffusion models [ ] would be the best. But very often we don't care about sampling, we care about density estimation. We want to know the value of at a particular . Questions like, "what is the density of the image?" are common in practice for tasks like anomaly detection, or uncertainty estimation.
In this post, I'll show you how to estimate the density of , using diffusion models, but not using diffusion models. We will train a bunch of classifiers that learn to estimate the density by adding noise to your dataset, and then combine them to estimate the density. This is a very simple method to implement and seems to work quite well.
Problem Setup
Let's work with our trusty donut density,
def logpdf(x):
r = np.linalg.norm(x, axis=-1)
return -(r - 2.6)**2 / 0.033
Which looks like this,
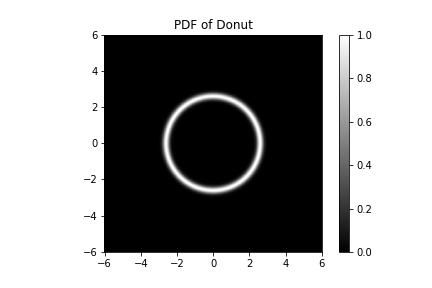
The PDF of our donut plotted. If you look a little closer, we see that the donut hole has a hole in its center - it is not a donut hole at all but a smaller donut with its own hole, and our donut is not a hole at all.
Let's generate some data from this distribution,
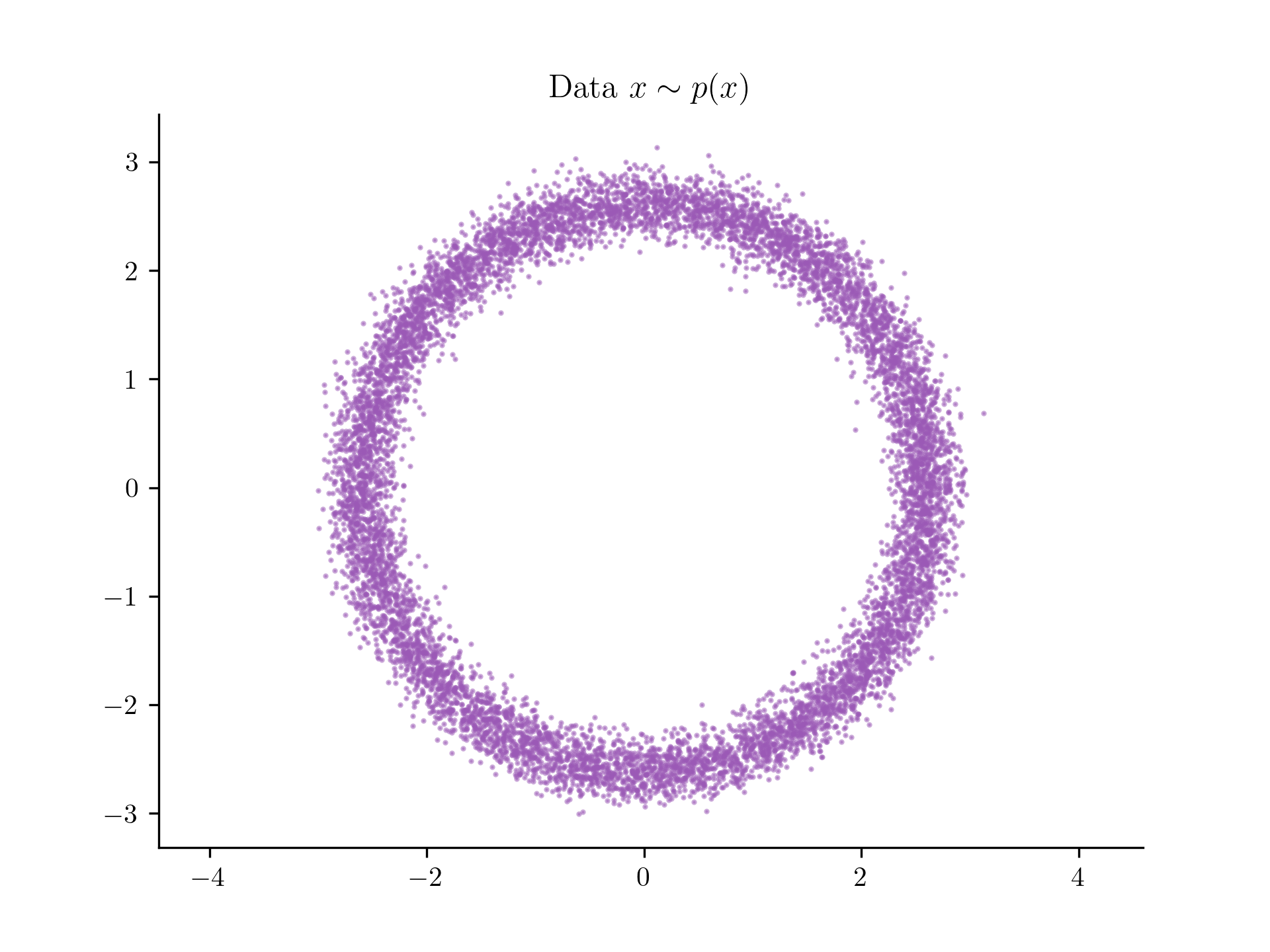
The dataset we'll be working with.
As you can see we have , and we have a dataset of examples. Our goal is to be able to evaluate the density of at any point , using only this dataset, .
Density Estimation via Classification
In the most basic setup, we can train a neural network to learn this density from this dataset by simply doing classification. We will train a neural network to classify whether a point is coming from or another dataset . This is generated from a distribution that is very easy to sample from, like a Gaussian or a uniform distribution. We can train this neural network to simply do binary classification, and then use the output of this network to estimate the density.
- Our dataset
- Our proposal distribution
Let be a neural network that models the probability that point came from either or . We can write this as,
Using Equation 1, we can estimate the density of at any point by evaluating at that point. We can train by minimizing the binary cross-entropy loss. Let's pick to be a Uniform distribution over the range . We can generate a dataset from this distribution.
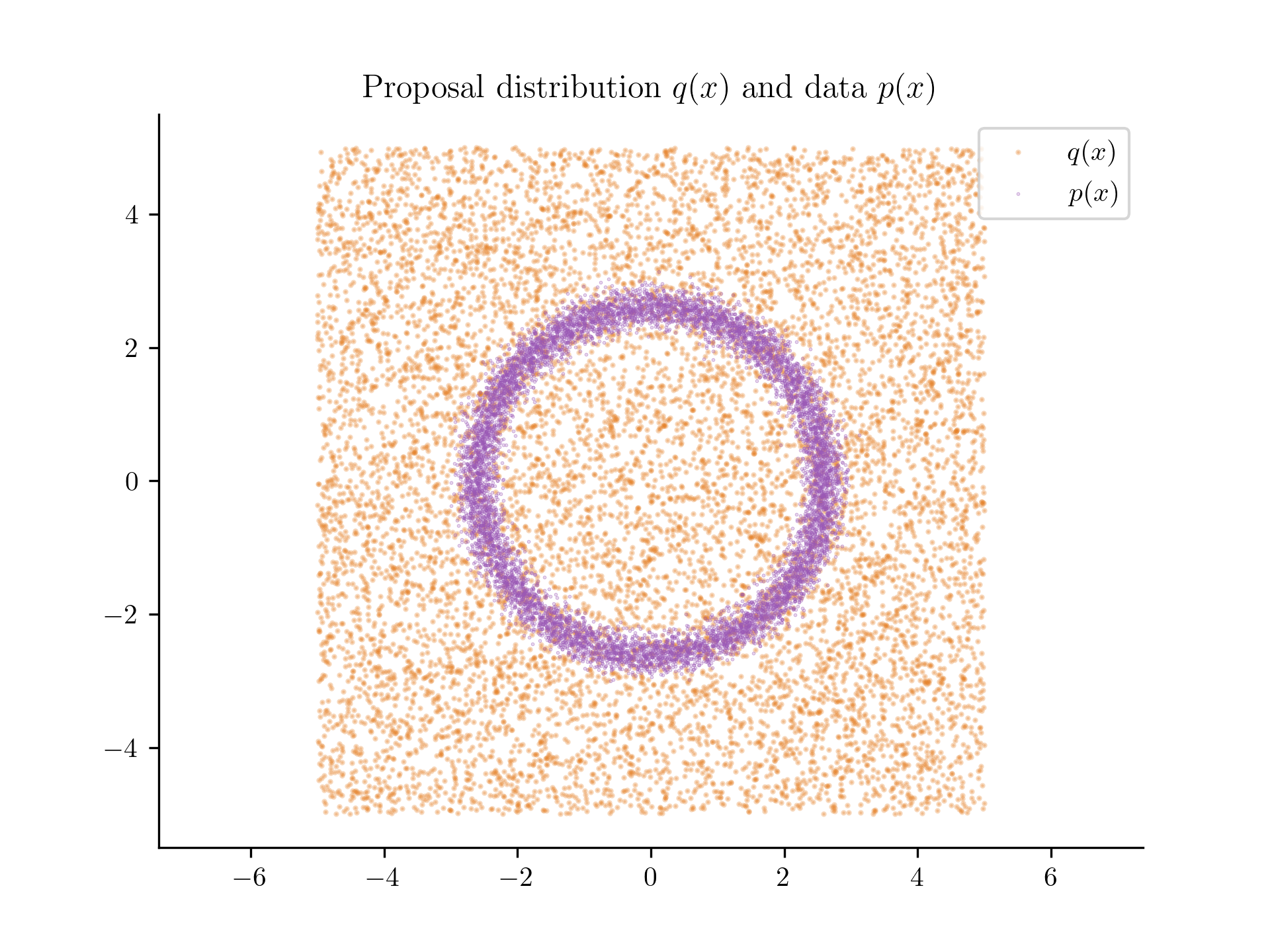
The proposal distribution (in orange) and the data points (in blue).
For numerical stability, we will actually train things using the following logistic loss from [ ],
This loss will estimate the density ratio between and ,
Where is the output of the neural network with an additional exponential transformation. This is done to ensure that the output of the neural network is always positive.
Now, our task for the neural network is to classify whether a point is coming from the blue distribution or the orange distribution.
Let's define our neural network,
class DensityModel(nn.Module):
def __init__(self):
super(DensityModel, self).__init__()
self.fc1 = nn.Linear(2, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
This takes in a point and outputs a single value.
We can then train using the following code,
batch_size = 128
num_steps = 10000
def sample_batch():
data_idx = np.random.choice(len(data), batch_size // 2)
proposal_idx = np.random.choice(len(proposal_dataset), batch_size // 2)
data_batch = torch.tensor(data[data_idx], dtype=torch.float32)
proposal_batch = torch.tensor(proposal_dataset[proposal_idx], dtype=torch.float32)
return torch.cat([data_batch, proposal_batch], dim=0)
def loss_fn(model, x):
ratios = torch.exp(model(x))
ratios_p = ratios[:batch_size // 2]
ratios_q = ratios[batch_size // 2:]
return torch.mean(-torch.log(ratios_p / (ratios_p + 1)) - torch.log(1 / (ratios_q + 1)))
model = DensityModel()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for step in range(num_steps):
optimizer.zero_grad()
x = sample_batch()
loss = loss_fn(model, x)
loss.backward()
optimizer.step()
if step % 100 == 0:
print(f"Step {step}, loss: {loss.item()}")
Once the model is learned, we can get the predicted value of by evaluating the model at and exponentiating the output,
In this case is a uniform, which is a constant. So . We can then plot the density of at any point , by just calling the model at that point.
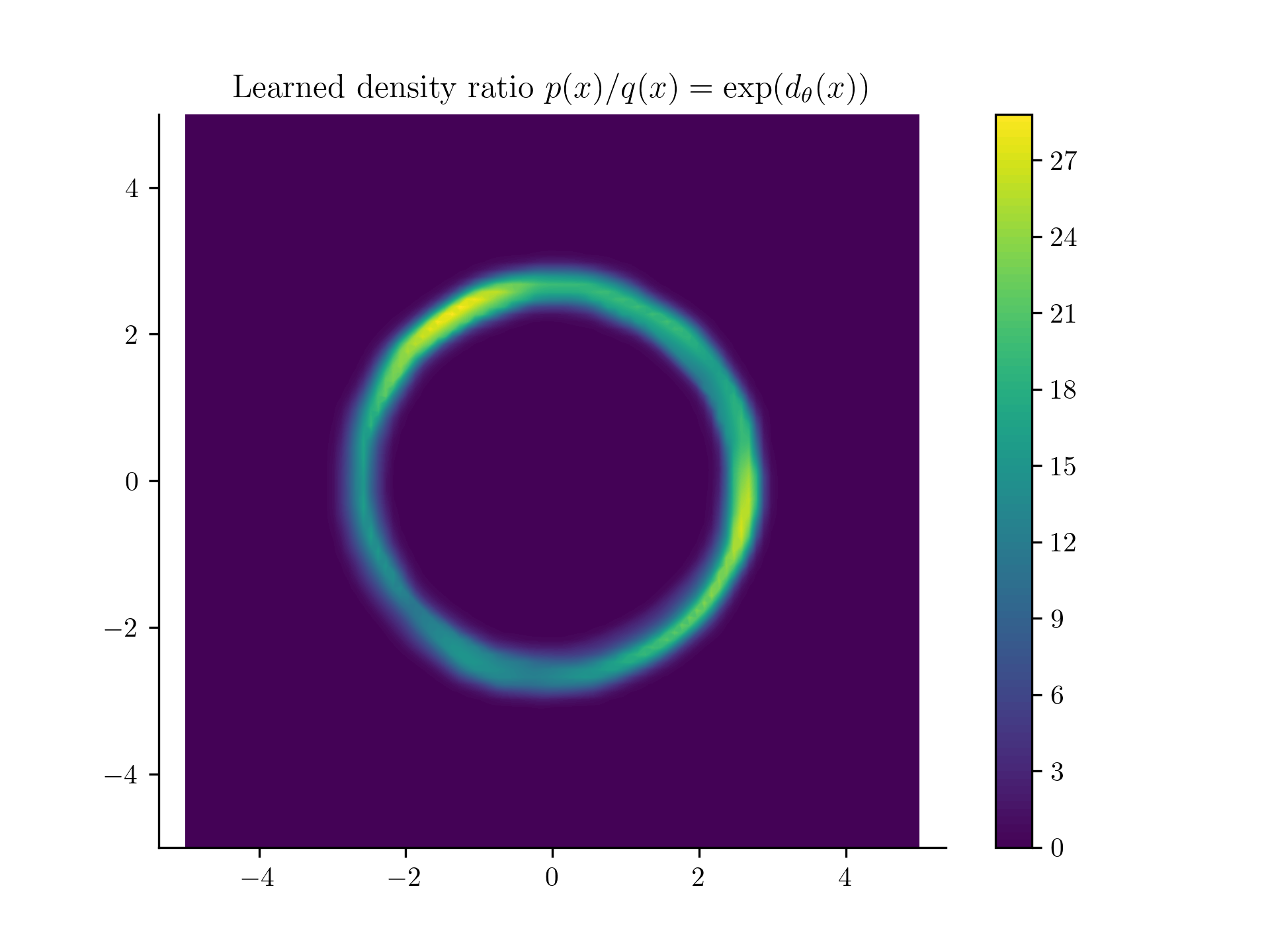
Our learned density from samples!
This doesn't look too bad! Next we'll see the problems with this approach and how to fix them.
Problems with Density Estimation via Classification
Recall that is the density we want to learn and we picked an easy density to help us train our classifier. We picked to be a uniform distribution over the range . What if we picked a different ? Would our classifier still work?
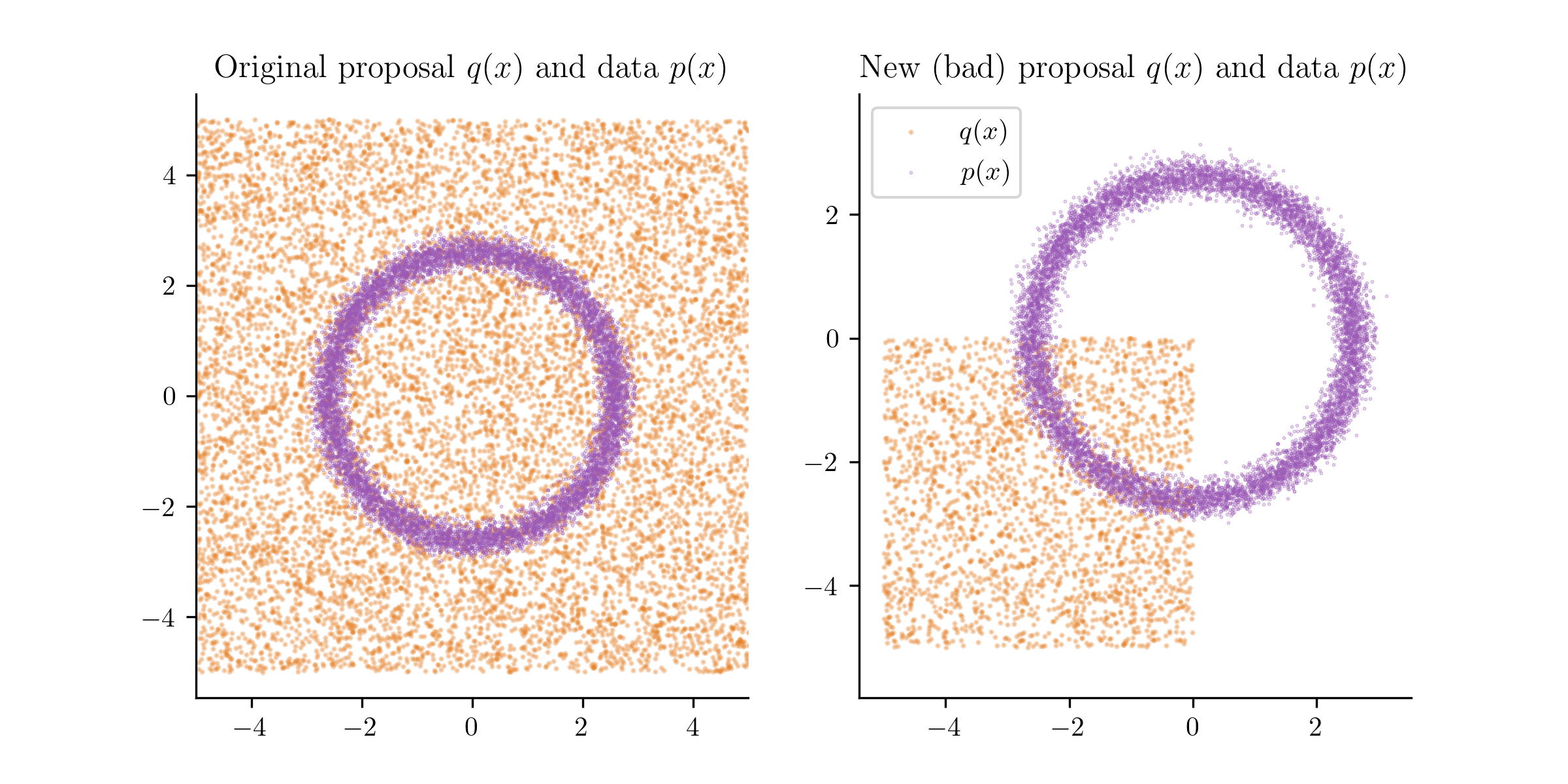
The new proposal distribution (in orange) and the data points (in blue).
Above, I show a new which is a uniform over the range . If we train our classifier on this new , we will get a very different density estimate,
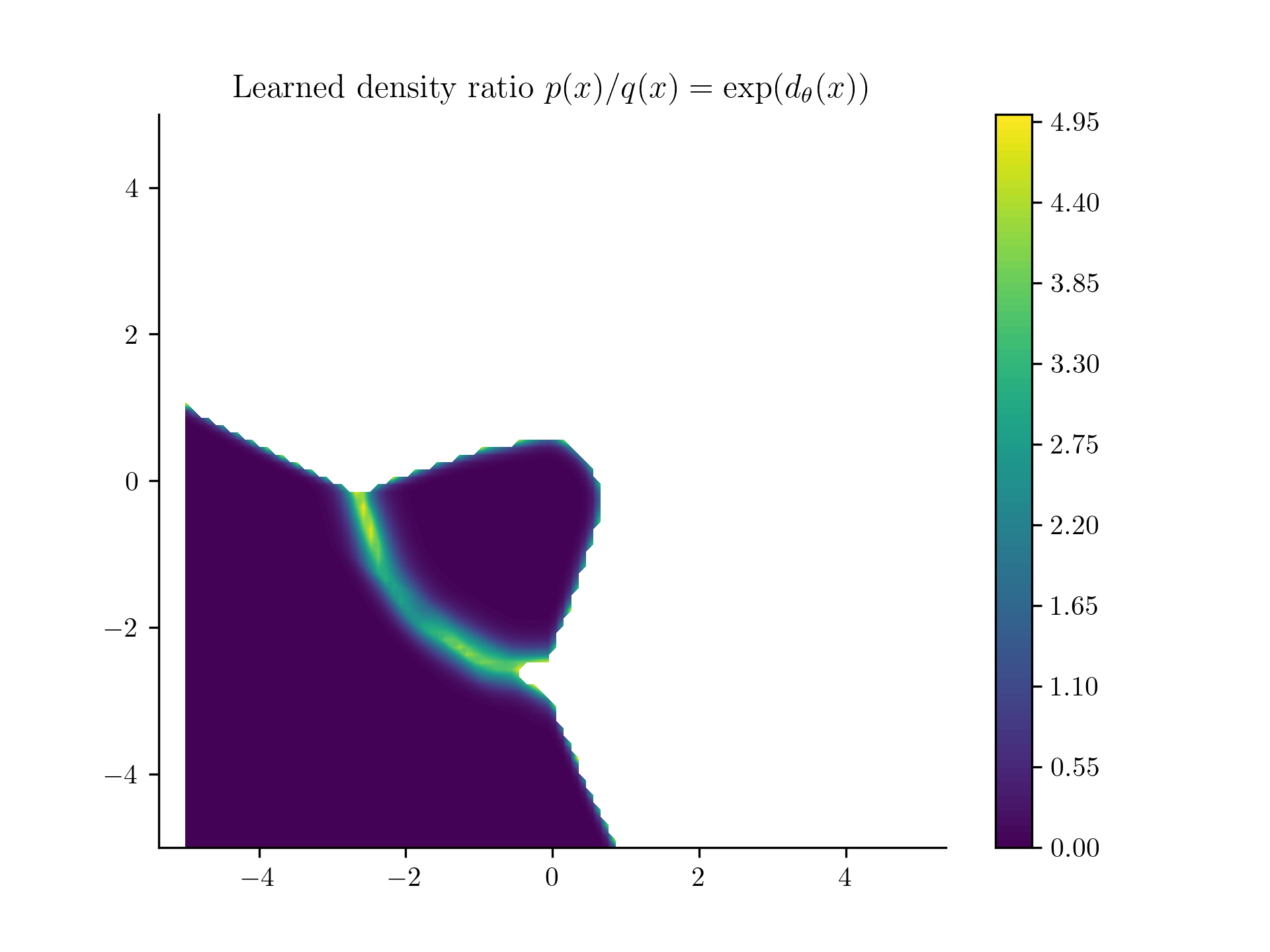
Yeah, that's sad. White values were basically NaNs.
What's happening here? In the lower-left quadrant, classifiying between the orange points and the blue points is an interesting problem. But on all the other quadrants, the task is too easy. The classifier can just learn to classify all points in that upper region as , even though that is not true. We simply don't have enough contrasting data for those points. So the choice of is very important.
Diffusion To The Rescue!
I'm mashing together the ideas from [ ] and [ ] here. We can fix the problem of choosing by ... just adding noise to our dataset! We can train a classifier to classify whether a point is coming from the original dataset or a noisy version of the dataset . We can then use the output of this classifier to estimate the density of . But this is still bad, because if we add too much noise to our dataset, we again have a very easy classification problem (think about making a density estimator for images, it is very easy to classify between gaussian noise and an image).
Instead, we'll incrementally add noise, just like in diffusion or score-based models.
Let be our original density. We will generate a sequence of densities by adding higher and higher amounts of noise to our dataset. For simplicity, we will add Gaussian noise to our dataset,
Here is some noise schedule that tells us the amount of noise for level . We can then train a classifier to classify whether a point is coming from or . So,
Note that our model now gets an additional input, the noise level , which tells the model which classification problem it's working on. To estimate the density of , we can use the telescoping product,
This method is has analogies to Simulated Annealing and the Langevin Monte Carlo method.
Okay! Let's implement this in code.
NUM_NOISE_SCALES = 10
NOISE_SCALES = [0.63096**scale_index for scale_index in range(NUM_NOISE_SCALES)][::-1]
FULL_NOISE_SCALES = np.array([0] + NOISE_SCALES)
for i, noise_scale in enumerate(FULL_NOISE_SCALES):
noised_data = data + np.random.normal(0, noise_scale, data.shape)
# Plot the noised data.
# ...
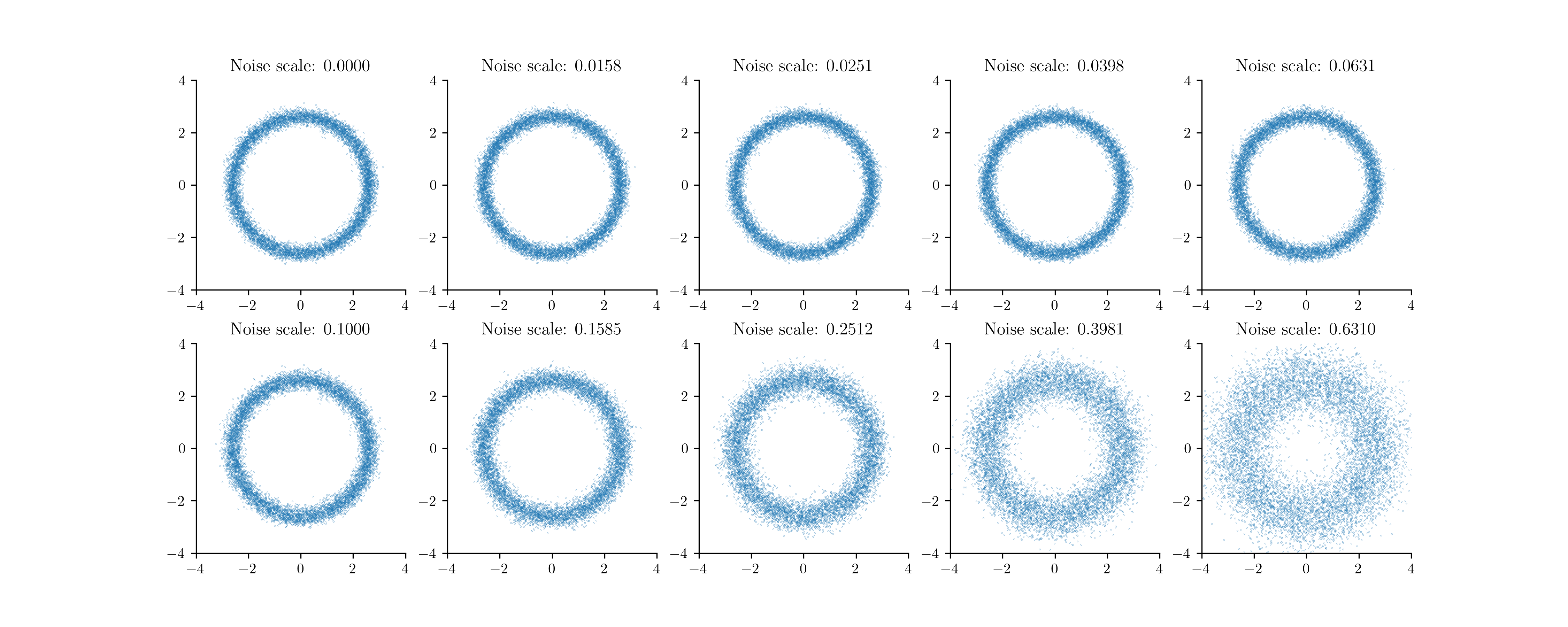
Our incremental distributions for the donut.
Let's modify out model so it takes in a and a noise level ,
class DensityModel(nn.Module):
def __init__(self):
super(DensityModel, self).__init__()
self.fc1 = nn.Linear(3, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 1)
def forward(self, x, sigmas):
# x.shape = (batch_size, 2)
# sigmas.shape = (batch_size, 1)
# Concatenate the sigmas to the input to get a (batch_size, 3) tensor.
x = torch.cat([x, sigmas], dim=1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
We can then train the model using the following code,
batch_size = 128
num_steps = 10000
def sample_batch():
noise_levels = np.random.randint(0, NUM_NOISE_SCALES, batch_size // 2)
pre_sigmas = FULL_NOISE_SCALES[noise_levels]
post_sigmas = FULL_NOISE_SCALES[noise_levels + 1]
data_idx_pre = np.random.choice(len(data), batch_size // 2)
data_batch_pre = data[data_idx_pre]
data_idx_post = np.random.choice(len(data), batch_size // 2)
data_batch_post = data[data_idx_post]
pre_data = data_batch_pre + np.random.normal(0, pre_sigmas[:, None], data_batch_pre.shape)
post_data = data_batch_post + np.random.normal(0, post_sigmas[:, None], data_batch_post.shape)
data_batch = np.concatenate([pre_data, post_data], axis=0)
sigmas = np.concatenate([post_sigmas, post_sigmas], axis=0)
return torch.tensor(data_batch, dtype=torch.float32), torch.tensor(sigmas, dtype=torch.float32)[:, None]
def loss_fn(model, x, sigmas):
ratios = torch.exp(model(x, sigmas))
ratios_p = ratios[:batch_size // 2]
ratios_q = ratios[batch_size // 2:]
return torch.mean(-torch.log(ratios_p / (ratios_p + 1)) - torch.log(1 / (ratios_q + 1)))
model = DensityModel()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for step in range(num_steps):
optimizer.zero_grad()
x, sigmas = sample_batch()
loss = loss_fn(model, x, sigmas)
loss.backward()
optimizer.step()
if step % 100 == 0:
print(f"Step {step}, loss: {loss.item()}")
And .. drumroll please,
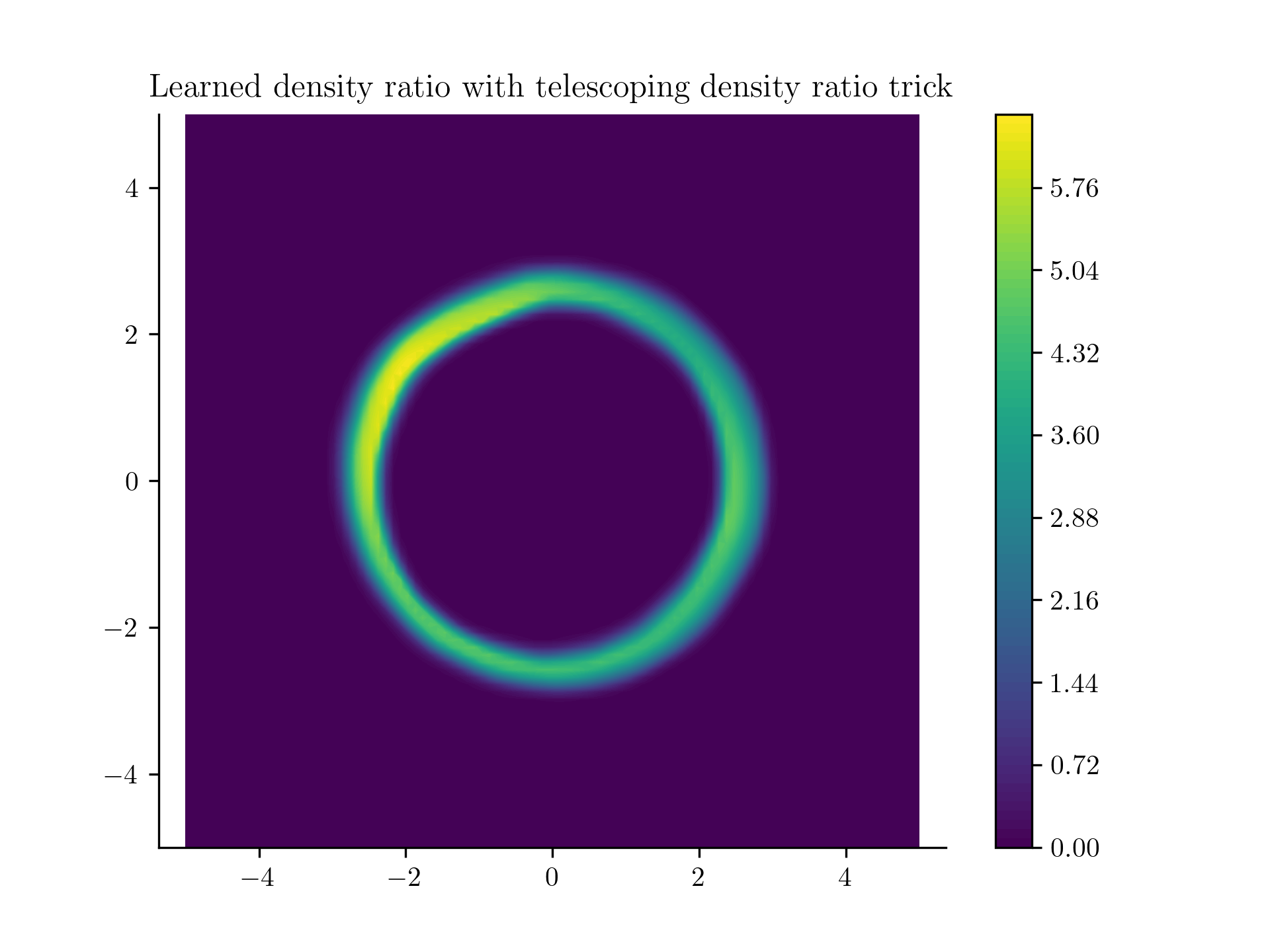
Learned density using the incremental noise levels!
Here is a little animation of it learning,
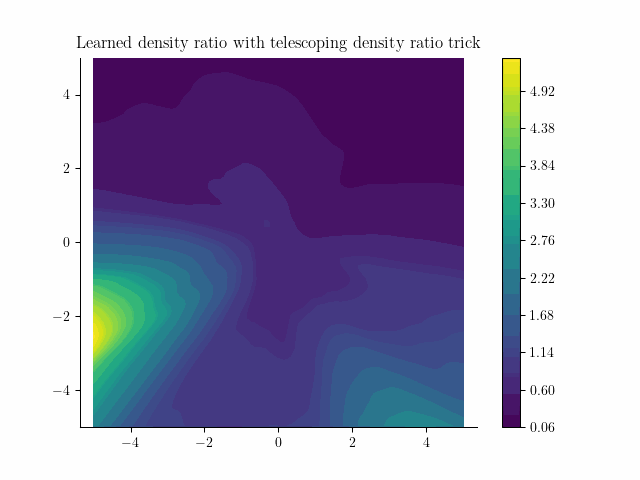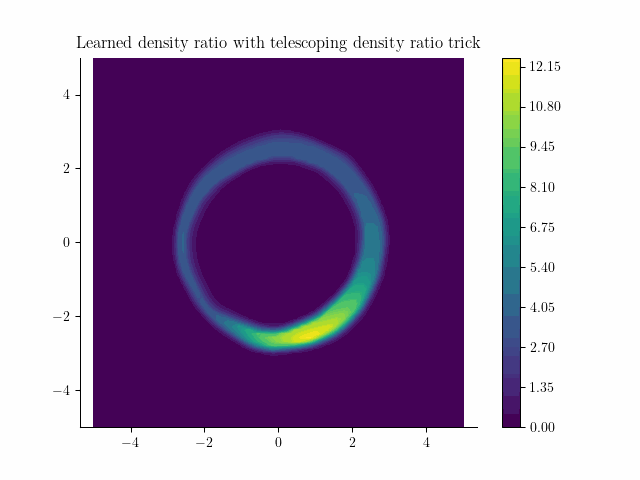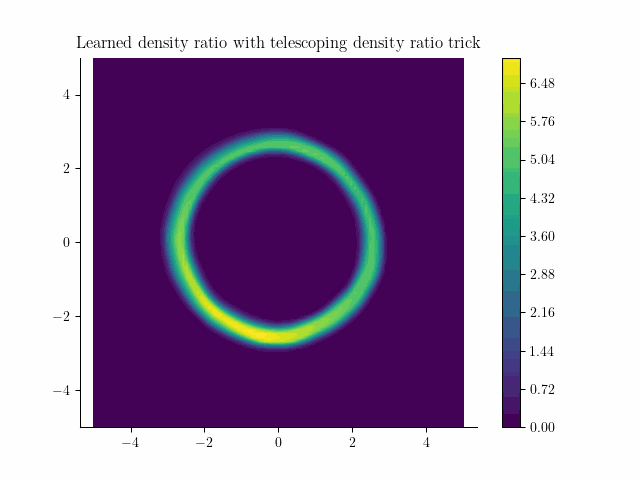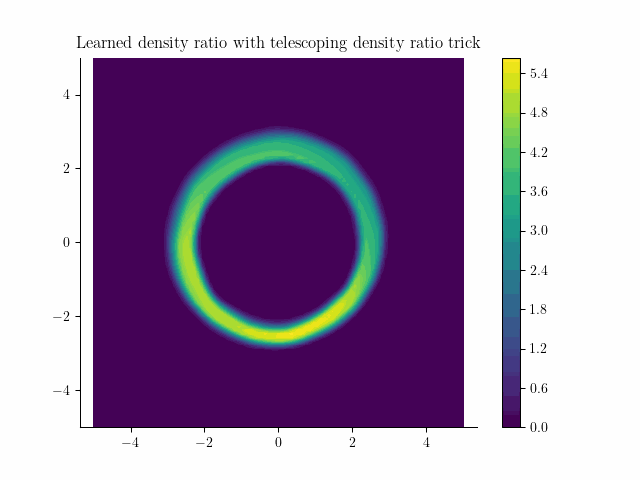
Learned density using the incremental noise levels!
You can find the full code for this blog post here.
Citation
@misc{kapur2024density,
url={https://shreyaskapur.com/blogs/density},
journal={Neural Density Estimation via Diffusion},
author={Kapur, Shreyas},
year={2024},
month={Jul}
}