

Score Manipulation in The Indian Education System
In 2013, Debarghya Das analyzed about 150,000 exam results for the ICSE board. Inspired by his work, I managed to do the same for the 2016 CBSE results, downloading the results of over ~1,000,000 candidates.
The Data
The length of the data was a little over a million records. This is less than the actual number of candidates since I did not handle all special cases (like result withheld or unfair means).
The following is the distribution of average of best subjects (x-axis) against the number of students (y-axis). The y-axis is cut off at the peak of the distribution for scaling it properly.
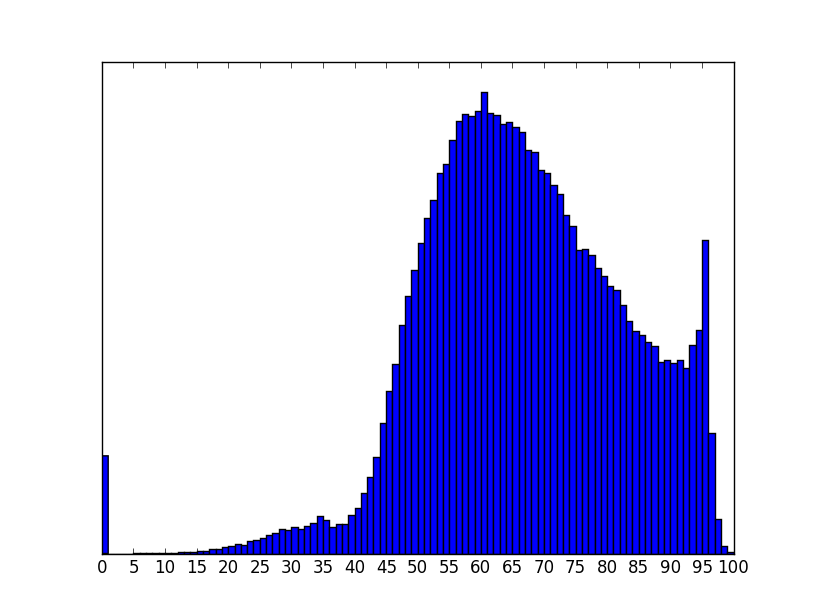
(Best Of 4 subjects, )
It's interesting to note how there is a spike at 95 and a small peak around 35. This might be explained from the subject graphs.
The following is the distribution of English Core (Subject Code: 301)
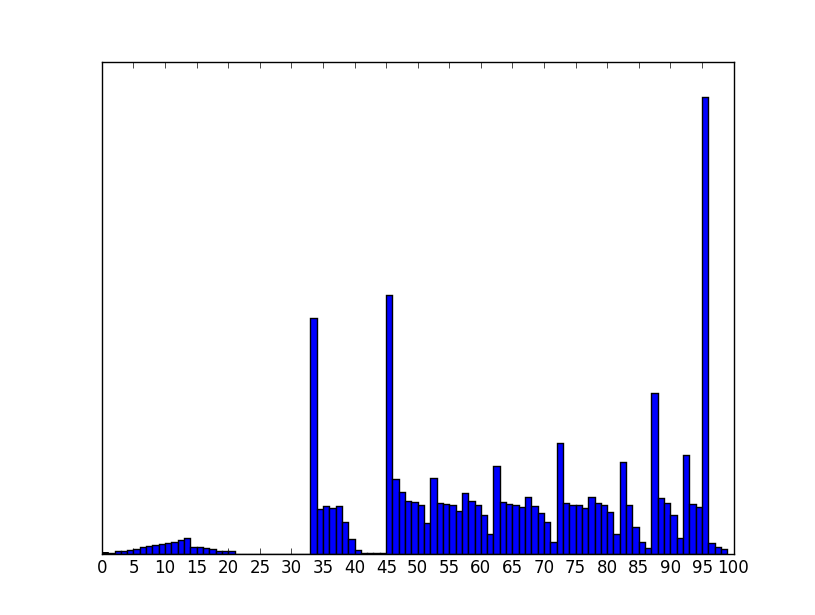
Not a single student scored a 100 and 12% of all candidates received a 95. The peaks in the distribution are indicative of artificial digitization.
The following is the distribution for Mathematics (Subject Code: 041)
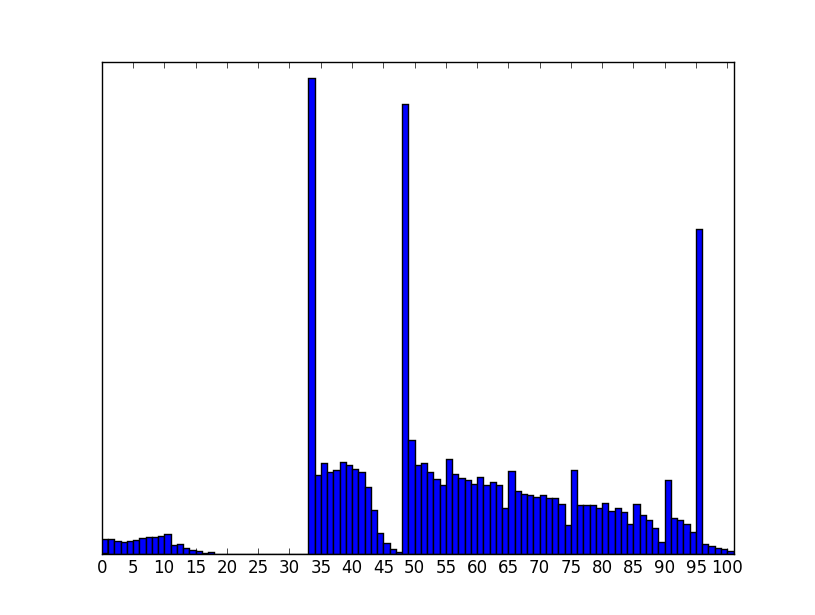
A key feature of this data distribution is that 33 is the passing score. A seemingly empty region from 17 to 33 and a big peak at 34 indicates that the results were artificially manipulated to pass a lot more students.
"Hey, I barely passed! Right?"
The rest of the data distributions for all other subjects like Physics, Chemistry, and others can be found at the original Medium Post.
I also ran all the names through Facebook to get gender data. During the time of writing, non-binary data was no available through Facebook, and hence was left out. The overall gender ratio was 50.3% males and 49.7% females.
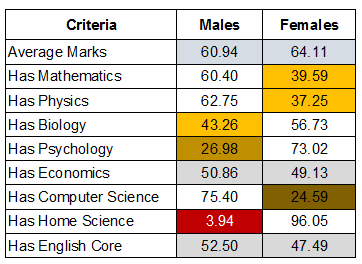
This table shows the various ratios of the subjects males vs females chose. Economics was the most even subject, and Home Science the most skewed.
Scores secured by males and females were generally comparable, with females scoring a few fractions of a point more than males. A notable exception was Psychology, with, on average, females scoring 9 more points than males.
Disclaimer: There might be mistakes that have crept in after parsing all the data. I've tried my best to be as careful as I can, and I sincerely apologize for any errors.